import json
import tarfile
import matplotlib.pyplot as plt
import numpy as np
import pyhf
import pyhf.contrib.utils
import scipy
from pyhf.contrib.viz import brazil
pyhf.set_backend("numpy", "minuit")
from rich import box
from rich.console import Console
from rich.table import TableModel-Independent Upper Limits¶
This section is aiming to cover some common concepts about (model-independent) upper limits. While it won’t necessarily be exhaustive, the aim is to summarize the current working knowledge of how High Energy Physics experiments such as ATLAS produce tables such as Table 20 from the Supersymmetry Electroweak 2-lepton, 2-jet analysis (SUSY-2018-05):
Table 20: Model-independent upper limits on the observed visible cross-section in the five electroweak search discovery regions, derived using pseudo-experiments. Left to right: background-only model post-fit total expected background, with the combined statistical and systematic uncertainties; observed data; 95 CL upper limits on the visible cross-section ($\langle A\varepsilon\sigma\rangle_\mathrm{obs}^{95}$) and on the number of signal events ($\mathrm{S}_\mathrm{obs}^{95}$). The sixth column ($\mathrm{S}_\mathrm{exp}^{95}$) shows the expected 95 CL upper limit on the number of signal events, given the expected number (and $\pm1\sigma$ excursions of the expectation) of background events. The last two columns indicate the confidence level of the background-only hypothesis ($\mathrm{CL}_\mathrm{b}$) and discovery $p$-value with the corresponding Gaussian significance ($Z(s=0)$). $\mathrm{CL}_\mathrm{b}$ provides a measure of compatibility of the observed data with the signal strength hypothesis at the 95 CL limit relative to fluctuations of the background, and $p(s=0)$ measures compatibility of the observed data with the background-only hypothesis relative to fluctuations of the background. The $p$-value is capped at 0.5.
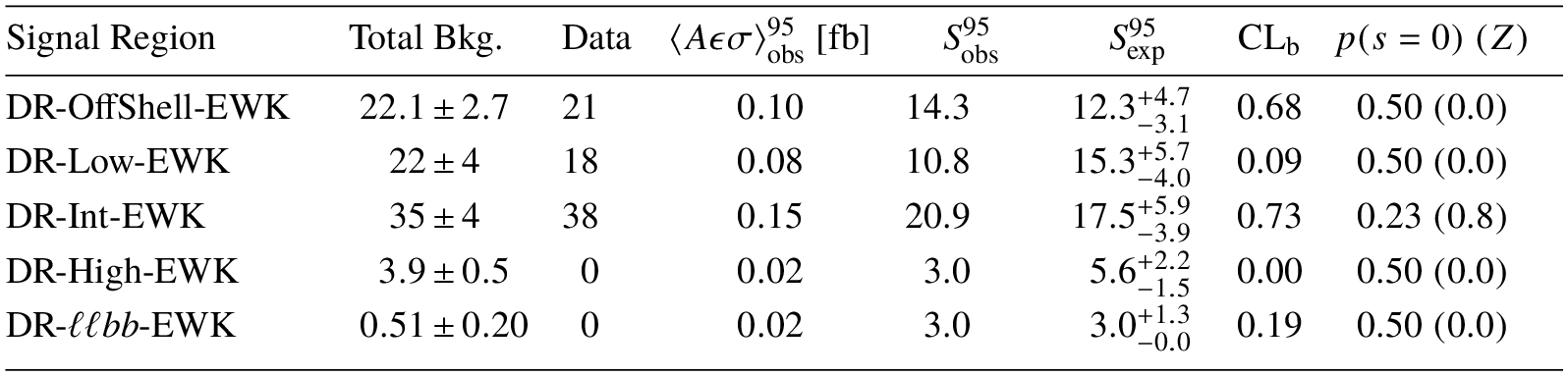
Here, the ATLAS collaboration provided some text describing each of the individual columns. How does that translate to statistical fits and pyhf? Let’s explore below. We will use the public probability models from the analysis published on HEPData entry.
Downloading the public probability models¶
First, we’ll use pyhf.contrib to download the models from HEPData:
pyhf.contrib.utils.download(
"https://doi.org/10.17182/hepdata.116034.v1/r34", "workspace_2L2J"
)Then use Python’s tarfile (part of standard library) to extract out the JSONs:
with tarfile.open("workspace_2L2J/ewk_discovery_bkgonly.json.tgz") as fp:
bkgonly = pyhf.Workspace(json.load(fp.extractfile("ewk_discovery_bkgonly.json")))
with tarfile.open("workspace_2L2J/ewk_discovery_patchset.json.tgz") as fp:
patchset = pyhf.PatchSet(json.load(fp.extractfile("ewk_discovery_patchset.json")))and then build our workspace for a particular signal region DR-Int-EWK:
ws = patchset.apply(bkgonly, "DR_Int_EWK")
model = ws.model()Understanding expected and observed events¶
The background estimate(s) in the signal region(s) are obtained from the background-only fit to control region(s) extrapolated to the signal region(s).
This number, combined with the number of observed events in the signal region, allows us to redo the limit-setting or -value determination without the public probability models.
For the uncertainties on the background estimate(s) in the signal region(s), they’re symmetric and calculated through standard error propagation described below.
Observed Events¶
The observed events are just ws.data(model) which we will call data. These are ordered in the same way as the ordering of the channels in the model (model.config.channels):
data = ws.data(model)
print(list(zip(model.config.channels, data)))Expected Events¶
The expected events are determined from a background-only fit. This is done by fixing the parameter of interest (i.e. for a search the non-SM signal strength) to zero. This fit will give us the fitted parameters . From this, we can print out the expected background events in each channel after this fit:
pars_uncrt_bonly, corr_bonly = pyhf.infer.mle.fixed_poi_fit(
0.0, data, model, return_uncertainties=True, return_correlations=True
)
pars_bonly, uncrt_bonly = pars_uncrt_bonly.T
table = Table(title="Per-region yields from background-only fit", box=box.HORIZONTALS)
table.add_column("Region", justify="left", style="cyan", no_wrap=True)
table.add_column("Total Bkg.", justify="center")
for region, count in zip(model.config.channels, model.expected_actualdata(pars_bonly)):
table.add_row(region, f"{count:0.2f}")
console = Console()
console.print(table)The uncertainty on the total background (expected event rate) is done by linearly propagating errors on parameters using the covariance matrix from a fit result. The error is calculated in the same way that ROOT’s RooAbsReal::getPropagatedError() calculates it. It is summarized as follows
where
with the probability model and the vector of one-sigma uncertainties of all fit parameters taken from the fit result and the correlation matrix from the fit result.
References:
Note: be aware that some definitions of error propagation use covariance and some use correlation. You can translate between the two, turning covariance into correlation by multiplying by on both sides. If one uses covariance, you’ll need information about the derivatives (e.g. through auto-differentiation).
This could be done with a for-loop like so:
up_yields = []
dn_yields = []
for i, variation in enumerate(uncrt_bonly):
varied_up_pars = pars_bonly[:] # copy
varied_up_pars[i] += variation
varied_dn_pars = pars_bonly[:] # copy
varied_dn_pars[i] -= variation
up_yields.append(model.expected_actualdata(varied_up_pars))
dn_yields.append(model.expected_actualdata(varied_dn_pars))which gives us the up/down variations on the yields for each systematic. However, we’ll batch this calculation to calculate all yield variations simultaneously. To do this, we set up our model to allow for batching.
npars = len(model.config.parameters)
model_batch = ws.model(batch_size=npars)
pars_batch = np.tile(pars_bonly, (npars, 1))Then we calculate the up_yields and dn_yields which are used to calculate the term above, denoted as variations:
up_yields = model_batch.expected_actualdata(pars_batch + np.diag(uncrt_bonly))
dn_yields = model_batch.expected_actualdata(pars_batch - np.diag(uncrt_bonly))
variations = (up_yields - dn_yields) / 2Now we can calculate :
error_sq = np.einsum("il,ik,kl->l", variations, corr_bonly, variations)
error_sqTaking the square root will give us the propagated uncertainty on the yields per-region for the background-only fit. We can update our table:
table = Table(title="Per-region yields from background-only fit", box=box.HORIZONTALS)
table.add_column("Region", justify="left", style="cyan", no_wrap=True)
table.add_column("Total Bkg.", justify="center")
for region, count, uncrt in zip(
model.config.channels, model.expected_actualdata(pars_bonly), np.sqrt(error_sq)
):
table.add_row(region, f"{count:0.2f} ± {uncrt:0.2f}")
console = Console()
console.print(table)Understanding visible cross-section¶
See ATL
Production cross section upper limits is another way of saying model-dependent limits. Without the detector efficiency (but keeping selection acceptance), the term visible cross section upper limits is used.
For upper limits on numbers of events (and the corresponding cross section), after detector efficiency and selection acceptance effects, the term model independent upper limits is used. These upper limits are typically free from assumptions about the acceptance and efficiency of any model (and are model independent in that sense), but they do make the assumption that signal contamination in control regions is negligible.
Model-independent Upper Limits¶
Model-independent upper limits (UL) at the 95% confidence level (CL) on the number of beyond the SM (BSM) events for each signal region are derived using the prescription (DOI: Read (2002)) and neglecting any possible contamination in the control regions.
To obtain the 95% CL model-independent UL / discovery -value, the fit in the signal region proceeds in the same way as the background-only fit, except that an additional parameter for the non-SM signal strength, constrained to be non-negative, is fit.
pyhf.set_backend("numpy", "scipy")
mu_tests = np.linspace(15, 25, 10)
(
obs_limit,
exp_limit_and_bands,
(poi_tests, tests),
) = pyhf.infer.intervals.upper_limits.upper_limit(
data, model, scan=mu_tests, level=0.05, return_results=True
)print(f"Observed UL: {obs_limit:0.2f}")
print(
f"Expected UL: {exp_limit_and_bands[2]:0.2f} [{exp_limit_and_bands[1]-exp_limit_and_bands[2]:0.2f}, +{exp_limit_and_bands[3]-exp_limit_and_bands[2]:0.2f}]"
)When calculating (also for expected) it is typical to inject a test signal (all expected event rates equal to unity) which means for this signal, we’re assuming . As is an upper limit on for this test signal, normalizing this by the integrated luminosity of the data sample allows us to interpret as upper limits on the visible (BSM) cross-section, . This is defined as the product of acceptance, reconstruction efficiency and production cross-section.
Remember that we often call this the visible cross-section, where cross-section is and the visible cross-section is . This is called a model independent limit as we do not have a specific model in mind (hence the test signal). We don’t have specific values for selection acceptance , detector efficiency , or signal model cross-section , so we can only say something about the product. If we have a specific signal model with that gives us a cross-section higher than the limit on the visible cross-section, we should be able to see that signal in the analysis.
print(f"Limit on visible cross-section: {obs_limit / 140:0.2f} ifb") # 140 ifbDiscovery -values¶
The significance of an excess can be quantified by the probability () that a background-only experiment is more signal-like than observed. The last two columns indicate the value and the discovery -value () with the corresponding gaussian significance ().
These two numbers provide information about the compatibility of the observed data with a background-only hypothesis, albeit with different test statistics . The (or ) test statistic is optimized for hypothesis-testing the signal+background hypothesis. The test statistic is optimized for hypothesis-testing the background-only hypothesis.
From Equation 52 in arXiv:1503.07622:
for : the null hypothesis is signal at a rate and the alternative hypothesis is signal at a rate of
for : the null hypothesis is background-only (b) and alternative hypothesis is signal+background (s+b)
For these hypotheses, we find that the -values are
and
Note that the same value is used to determine and .
(and )¶
provides a measure of compatibility of the observed data with the 95% CL signal strength hypothesis relative to fluctuations of the background. is evaluating in the case where and (the fitted at the upper limit ). This is saying that the tested is the 95% CL signal strength () but the assumed true is the background-only hypothesis ():
Note that this calculation depends on the value of at the fitted upper limit . You get a small if you have a downward fluctuation in observed data relative to your signal+background hypothesis, preventing you from excluding your signal erroneously if you “shouldn’t be able to” when using (since you would be dividing by a small number). See the paragraph above plot on page two in this document.
¶
measures compatibility of the observed data with the background-only (zero signal strength) hypothesis relative to fluctuations of the background. Larger values indicate greater relative compatibility. is not calculated in signal regions with a deficit with respect to the nominal background prediction.
This is saying that the tested is the background-only hypothesis () and the assumed true is the background-only hypothesis:
Relationship to ¶
This will be covered through a learn notebook, which will be added as part of scikit
Calculating the -values¶
Armed with all of this knowledge, we can first calculate the discovery -value evaluated at , as well as convert this to a Z-score assuming a “standard” Normal distribution:
p0 = pyhf.infer.hypotest(0.0, data, model, test_stat="q0")
p0_Z = scipy.stats.norm.isf(p0)
print(f"p(s)=0 (Z): {p0:0.2f} ({p0_Z:0.2f})")And similarly, we can extract by evaluating at :
_, (_, CLb) = pyhf.infer.hypotest(obs_limit, data, model, return_tail_probs=True)
print(f"CLb: {CLb:0.2f}")Making the table¶
Now that we have all of our numbers, we can make the table for the discovery region DRInt_cuts. We’ll get the corresponding index of the channel so we can extract out the total background and uncertainty estimates from above.
region_mask = model.config.channels.index("DRInt_cuts")
bkg_count = model.expected_actualdata(pars_bonly)[region_mask]
bkg_uncrt = np.sqrt(error_sq)[region_mask]table = Table(
title="Model-independent upper limits on the observed visible cross-section in the five electroweak search discovery regions; derived using asymptotics, pyhf, and published likelihoods.",
box=box.HORIZONTALS,
)
table.add_column("Signal Region", justify="left", style="cyan", no_wrap=True)
table.add_column("Total Bkg.", justify="center")
table.add_column("Data")
table.add_column(r"XSec \[fb]")
table.add_column("S 95 Obs")
table.add_column("S 95 Exp")
table.add_column("CLb(S 95 Obs)")
table.add_column("p(s=0) (Z)")
table.add_row(
model.config.channels[region_mask],
f"{bkg_count:0.0f} ± {bkg_uncrt:0.0f}",
f"{data[region_mask]:0.0f}",
f"{obs_limit / 140:0.2f}",
f"{obs_limit:0.1f}",
f"{exp_limit_and_bands[2]:0.1f} + {exp_limit_and_bands[3] - exp_limit_and_bands[2]:0.1f} - {exp_limit_and_bands[2] - exp_limit_and_bands[1]:0.1f}",
f"{CLb:0.2f}",
f"{p0:0.2f} ({p0_Z:0.1f})",
)
console = Console()
console.print(table)Table 20: Model-independent upper limits on the observed visible cross-section in the five electroweak search discovery regions, derived using pseudo-experiments. Left to right: background-only model post-fit total expected background, with the combined statistical and systematic uncertainties; observed data; 95 CL upper limits on the visible cross-section ($\langle A\varepsilon\sigma\rangle_\mathrm{obs}^{95}$) and on the number of signal events ($\mathrm{S}_\mathrm{obs}^{95}$). The sixth column ($\mathrm{S}_\mathrm{exp}^{95}$) shows the expected 95 CL upper limit on the number of signal events, given the expected number (and $\pm1\sigma$ excursions of the expectation) of background events. The last two columns indicate the confidence level of the background-only hypothesis ($\mathrm{CL}_\mathrm{b}$) and discovery $p$-value with the corresponding Gaussian significance ($Z(s=0)$). $\mathrm{CL}_\mathrm{b}$ provides a measure of compatibility of the observed data with the signal strength hypothesis at the 95 CL limit relative to fluctuations of the background, and $p(s=0)$ measures compatibility of the observed data with the background-only hypothesis relative to fluctuations of the background. The $p$-value is capped at 0.5.
Will Buttinger
Jonathan Long
Zach Marshall
Alex Read
Sarah Williams
Acknowledgments¶
We acknowledge the help of ATLAS Statistics Forum including:
- Read, A. L. (2002). Presentation of search results: theCLstechnique. Journal of Physics G: Nuclear and Particle Physics, 28(10), 2693–2704. 10.1088/0954-3899/28/10/313